[번역] 파이썬 GIL은 사라질까? (Has the Python GIL been slain?)

이 글은 원작자의 허락 하에 Anthony Shaw의 Has the Python GIL been slain? 을 번역한 글입니다.
2003년 초, 인텔은 "하이퍼스레딩" 기술을 포함한 3GHz 클럭의 새 Pentium 4 "HT" 프로세서를 출시했다.
몇년동안 Intel과 AMD는 버스 속도와 L2캐시 사이즈를 증가시키고 지연을 최소화 하기 위하여 다이 사이즈를 줄이는 등 최고의 성능을 달성하기 위하여 경쟁했고, 3GHz HT 프로세서는 단 1년만에 2004년에 4GHz의 클럭으로 작동하는 "프레스캇" 모델 580 으로 바뀌었다.
더 높은 성능을 달성하기 위해선 클럭 상승만이 유일한 답으로 보였으나 클럭이 올라갈 수록 CPU는 높은 전력 소모와 발열에 시달렸다.
그러나 예상 밖으로 성능을 올리는 것은 클럭이 아닌 버스 속도와 다중 코어였다. Intel 코어 2 프로세서는 펜티엄 4보다 낮은 클럭 속도를 가지고도 펜티엄 4 프로세서를 대체했다.
2006년은 소비자용 멀티코어 프로세서가 출시된 것 이외에도 with 문의 베타 버전이 포함된 파이썬 2.5가 출시된 해이기도 하다.
중요한 점은 파이썬 2.5는 다중 코어를 가진 Intel 코어 2와 AMD 애슬론 X2에 대한 커다란 제약을 포함하고 있었다는 것이다.
The GIL
GIL?
GIL(Global Interpreter Lock)은 파이썬 인터프리터에서 뮤텍스로 보호되는 불리언 값이다. GIL은 CPython의 코어 바이트코드 실행 루프가 현재 실행되고 있는 스레드를 지정하기 위해서 사용된다.
CPython은 하나의 인터프리터에서 여러개의 스레드를 실행하는 것을 지원하지만 스레드가 연산(OP 코드)를 실행하기 위해선 GIL에 대한 접근을 요청해야 한다. 다시말해 파이썬 개발자는 비동기 또는 멀티스레드 코드에서 변수에 대해 락을 걸거나 데드락이 걸려 프로세스가 충돌하는 것을 걱정할 필요가 없다는 것이다.
GIL은 멀티스레드 프로그래밍을 간단하게 하지만 한번에 한 스레드만이 실행될 수 있다는 것을 뜻하기도 한다. 즉, 쿼드코어 CPU를 이렇게 돌릴 수도 있다는 것이다. (아마도 블루스크린은 제외하고)

현재의 GIL은 비동기 지원을 추가하기 위하여 2009년에 만들어졌으며 GIL을 삭제하거나 의존을 줄이기 위한 많은 시도에도 불구하고 비교적 변경되지 않은 상태로 존재하고 있다.
GIL을 제거하기 위한 모든 제안에 요구되는 사항은 싱글 스레드 코드의 성능을 떨어트리지 말아야 한다는 것인데 2003년에 하이퍼스레딩을 써본 사람이라면 이것이 왜 중요한지 알 것이다.
CPython에서 GIL 피하기
CPython에서 진정한 병렬성을 원한다면 멀티프로세스를 사용해야 한다.
CPython 2.6에서 GIL을 가지고 있는 CPython 프로세스 스폰에 대한 래핑인 multiprocessing 모듈이 표준 라이브러리에 추가되었다.
from multiprocessing import Process
def f(name):
print 'hello', name
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
multiprocessing을 사용하면 프로세스를 스폰하여 컴파일된 파이썬 모듈(또는 함수)을 통해 명령을 보내고 마스터 프로세스에 복귀시킬 수 있다.
또한 multiprocessing 은 큐 또는 파이프를 통한 변수 공유와 다른 프로세스에서 쓰기 위해 마스터 프로세스의 객체를 잠그는 락을 지원힌디.
하지만 multiprocessing 은 메모리와 시간에 대해서 상당한 오버헤드를 가지고 있다. CPython의 시작에 걸리는 시간은 site를 제외하고도 100~200ms 가량이 소요된다. (이 글을 참고하자)
multiprocessing 을 통해 CPython에서 병렬적인 코드를 사용할 수 있지만 객체를 거의 공유하지 않는 장기 실행 프로세스들에 적용할 수 있도록 신중하게 계획해야 한다.
대안으로 Twisted 같은 서드파티 라이브러리를 사용할 수도 있다.
PEP554와 GIL의 죽음?
다시 정리해 보면 CPython에서 멀티스레딩은 편리하지만 진정한 동시성을 제공하는것은 아니며 멀티프로세싱은 진짜 동시성을 제공하지만 상당한 오버헤드를 가지고 있다는 것을 알 수 있다.
만약 더 좋은 방법이 있다면 어떨까?
GIL을 회피하는 방법에 대한 단서는 GIL의 이름에 있다. GIL, Global Interpreter Lock은 전역 인터프리터 상태의 일부다. CPython 프로세스는 여러개의 인터프리터를 가질 수 있기 때문에 여러개의 락이 가능하지만 이 기능은 C API를 통해서만 노출되기 때문에 거의 사용되지 않고 있다.
CPython 3.8에 제안되었던 기능 중 하나로 서브인터프리터 구현과 그 API인 interpreters 표준 라이브러리에 대한 PEP554가 있었다.
PEP554는 단일 프로세스 내에서 여러개의 인터프리터를 만들어 낼 수 있게 한다. 그리고 파이썬 3.8의 또 다른 변경중 하나는 각 인터프리터가 별개의 GIL을 가지게 된다는 것이다.
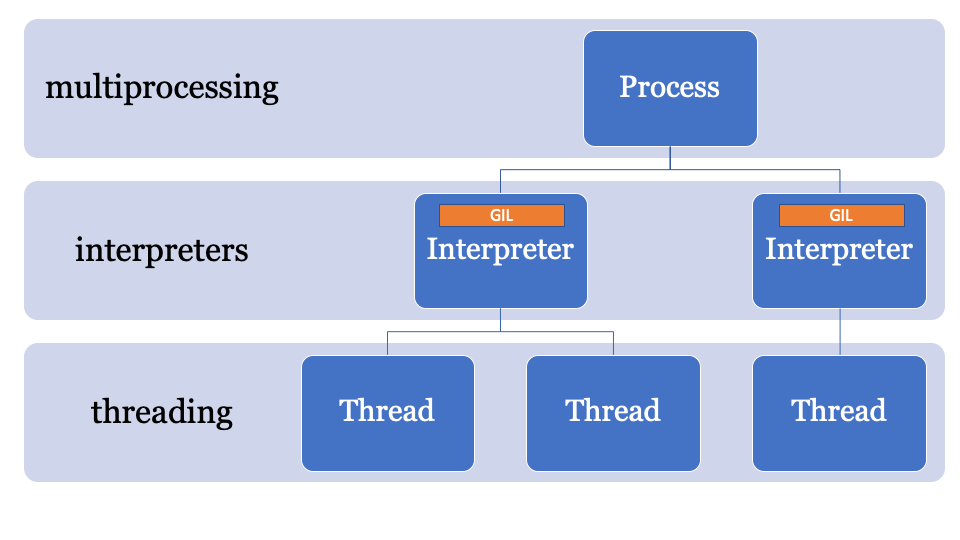
인터프리터 상태가 모든 파이썬 객체(지역과 전역 모두)의 포인터의 모음인 메모리 할당 영역을 가지고 있기 때문에 PEP554의 서브인터프리터는 다른 인터프리터의 전역 변수에 접근할 수 없다.
인터프리터 간에 객체를 공유하기 위해 멀티프로세싱처럼 객체를 직렬화하고 IPC의 형태를 사용할 수도 있다. 파이썬에는 객체를 직렬화하기 위한 다양한 방법을 가지고 있는데 (marshal, pickle 또는 좀 더 표준적인 json이나 simplexml) 각각의 방법은 장단점이 있지만 전부 오버헤드를 가지고 있다.
가장 좋은 방법은 소유하는 프로세스에 의해 컨트롤되는 변경 가능한 공유 메모리 공간을 가지는 것이다. 이런 방식에선 마스터 인터프리터에서 객체를 보낼수 있고 다른 인터프리터에서 객체를 받을 수도 있다. 이 방식 메인 프로세스가 락을 제어하며 각 인터프리터가 접근하는 PyObject 포인터의 lookup managed-memory space (lookup managed-memory space of PyObject pointers) 가 될 것이다.
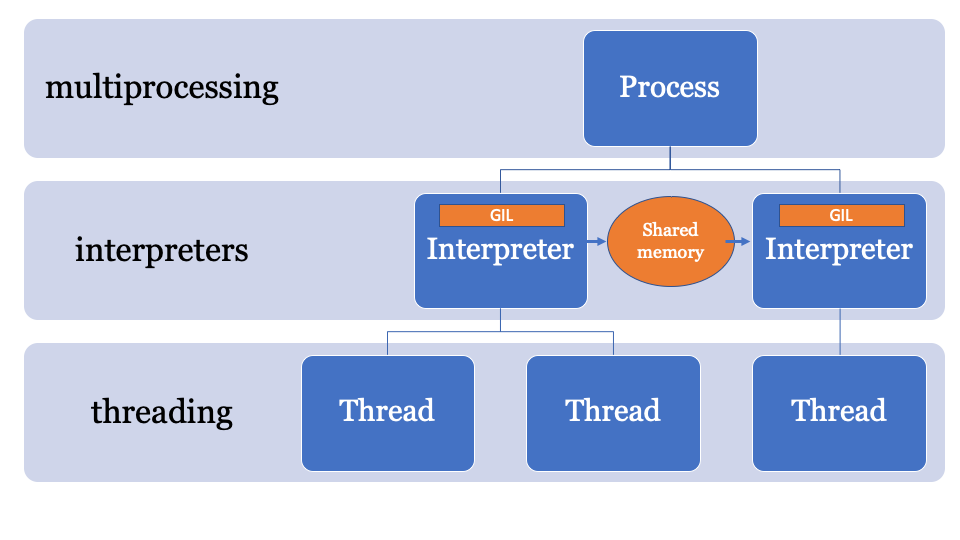
이를 위한 API는 개발중이지만 다음과 유사한 형태를 가지게 될 것이다.
import _xxsubinterpreters as interpreters
import threading
import textwrap as tw
import marshal
# Create a sub-interpreter
interpid = interpreters.create()
# If you had a function that generated some data
arry = list(range(0,100))
# Create a channel
channel_id = interpreters.channel_create()
# Pre-populate the interpreter with a module
interpreters.run_string(interpid, "import marshal; import _xxsubinterpreters as interpreters")
# Define a
def run(interpid, channel_id):
interpreters.run_string(
interpid,
tw.dedent("""
arry_raw = interpreters.channel_recv(channel_id)
arry = marshal.loads(arry_raw)
result = [1,2,3,4,5] # where you would do some calculating
result_raw = marshal.dumps(result)
interpreters.channel_send(channel_id, result_raw)
"""),
shared=dict(channel_id=channel_id),
)
inp = marshal.dumps(arry)
interpreters.channel_send(channel_id, inp)
# Run inside a thread
t = threading.Thread(target=run, args=(interpid, channel_id))
t.start()
# Sub interpreter will process. Feel free to do anything else now.
output = interpreters.channel_recv(channel_id)
interpreters.channel_release(channel_id)
output_arry = marshal.loads(output)
print(output_arry)
이 예제는 marshal 모듈을 사용하여 numpy 배열을 직렬화 하여 채널을 통해 보낸 다음 서브인터프리터기 각각의 GIL 위에서 데이터를 처리하게 하기 때문에 이 예제는 서브인터프리터에 딱 맞는 CPU 바운드 동시성 문제다.
흠... 비효율적인것 같은데
물론 marshal 모듈은 상당히 빠르지만 메모리에서 직접 객체를 공유하는 것만큼 빠르지는 않다.
PEP574에서 메모리 버퍼가 나머지 피클 스트림과 별도로 처리될 수 있도록 지원하는 새 Pickle v5 를 제안되었다. 대용량 데이터 객체의 경우 한번에 모두 직렬화 하고 서브인터프리터에서 역직렬화하게 되면 오버헤드가 늘어나게 된다.
새 API는 아마도 다음과 같이 표현될 것이다. (아마도)
import _xxsubinterpreters as interpreters
import threading
import textwrap as tw
import pickle
# Create a sub-interpreter
interpid = interpreters.create()
# If you had a function that generated a numpy array
arry = [5,4,3,2,1]
# Create a channel
channel_id = interpreters.channel_create()
# Pre-populate the interpreter with a module
interpreters.run_string(interpid, "import pickle; import _xxsubinterpreters as interpreters")
buffers=[]
# Define a
def run(interpid, channel_id):
interpreters.run_string(
interpid,
tw.dedent("""
arry_raw = interpreters.channel_recv(channel_id)
arry = pickle.loads(arry_raw)
print(f"Got: {arry}")
result = arry[::-1]
result_raw = pickle.dumps(result, protocol=5)
interpreters.channel_send(channel_id, result_raw)
"""),
shared=dict(channel_id=channel_id),
)
input = pickle.dumps(arry, protocol=5, buffer_callback=buffers.append)
interpreters.channel_send(channel_id, input)
# Run inside a thread
t = threading.Thread(target=run, args=(interpid, channel_id))
t.start()
# Sub interpreter will process. Feel free to do anything else now.
output = interpreters.channel_recv(channel_id)
interpreters.channel_release(channel_id)
output_arry = pickle.loads(output)
print(f"Got back: {output_arry}")
일단 이 예제는 저수준 서브인터프리터 API를 사용하고 있다. 만약 멀티프로세싱 라이브러리를 사용해 봤다면 API가 스레딩을 쓰는것만큼 단순하지 못하단 것을 알수 있을것이다. you can’t just say run this function with this list of inputs in separate interpreters (yet).
이 PEP가 병합되면 PyPI의 다른 API에도 적용될 것이라고 기대하고 있다.
서브인터프리터는 얼마나 무거운가
간단히 말하자면 스레드보다는 많지만 프로세스보다는 적다.
조금더 길게 설명하자면 인터프리터는 각자 자신만의 상태를 가지고 있다. 따라서 PEP554로 서브인터프리터를 쉽게 만들 수 있지만 다음의 것들을 클론하고 초기화 할 필요가 있다.
- __main__ 네임스페이스와 importlib안에 있는 모듈들
- sys 딕셔너리 포함
- assert 와 print 같은 내장 함수
- 스레드
- 코어 구성
코어 구성은 메모리에서 쉽게 클론할 수 있지만 임포트된 모듈을 클론하는 것은 간단하지 않다. 파이썬에서 모듈 임포트는 느린 작업이기 때문에 만약 서브인터프리터를 만드는 것이 매번 모듈을 다른 네임스페이스로 가져오는 것을 의미한다면 오버헤드가 적다는 장점은 줄어들게 된다.
asyncio는 어떨까?
현재 asyncio 표준 라이브러리에서 이벤트 루프의 구현체는 실행돨 프레임을 만들긴 해도 메인 인터프리터와 상태를 공유하기 때문에 GIL 또한 공유한다.
PEP554가 병합되고 나면 파이썬 3.9에서는 서브인터프리터로 비동기를 구현하는 대체 이벤트 루프가 구현될 수도 있다.
당장 쓸 수 있나요?
일단 아직은 갈 길이 멀다.
CPython은 오랫동안 단일 인터프리터 구조로 구현되었기 때문에 코드베이스의 많은 부분이 "인터프리터 상태" 대신 "런타임 상태"를 사용하므로 PEP554가 현재 상태 그대로 병합될 경우 많은 문제가 있을 수도 있다.
예를 들어, 3.7 버전 이하의 GC는 런타임에 속힌다.
PyCon 기간동안의 스프린트를 통해 GC 상태를 인터프리터로 옮겨서 지금은 각 서브인터프리터가 자신만의 GC를 갖게 되었다. (원래 그래야 했던대로)
또한 CPython 코드베이스와 많은 C 확장에 남아있는 "전역" 변수들이 몇가지 문제를 일으키게 될지도 모른다.
또 다른 문제는 파일 핸들이 프로세스에 속한다는 점이다. 지금은 만약 한 인터프리터에서 파일을 열면 다른 서브인터프리터는 그 파일에 액세스 할 수 없다. (CPython을 변경한다면 가능하다.)
한마디로 아직 해결해야 할 것들이 아주 많다.
결론: GIL은 사라졌는가
싱글 스레드 애플리케이션에 대한 GIL은 존재할 것이다. 즉, PEP554가 병합되더라도 싱글 스레드 코드가 병렬로 처리되지는 않을것이다.
If you want concurrent code in Python 3.8, you have CPU-bound concurrency problems then this could be the ticket!
그래서 언제?
Pickle v5와 멀티프로세싱을 위한 공유 메모리는 Python 3.8(2019년 10월)에 포함될 가능성이 높고 서브인터프리터는 3.8 또는 3.9에 포함될 것이다.
만약 예제들을 실행해보고 싶다면 필요한 코드를 갖춘 커스텀 브랜치를 만들어 두었다.